

結局のところ、僕らがやっていることは、AI様に役立つ学習データの提供に過ぎないんだろうか。
それも、ボランティアならまだしも、なんだったら費用を払ってまで、それに参加していることになる。
あわただしいTLから首を引っこ抜いて俯瞰してみれば、次の産業革命の覇権を握るためのデータ争奪戦が繰り広げられているようだ。
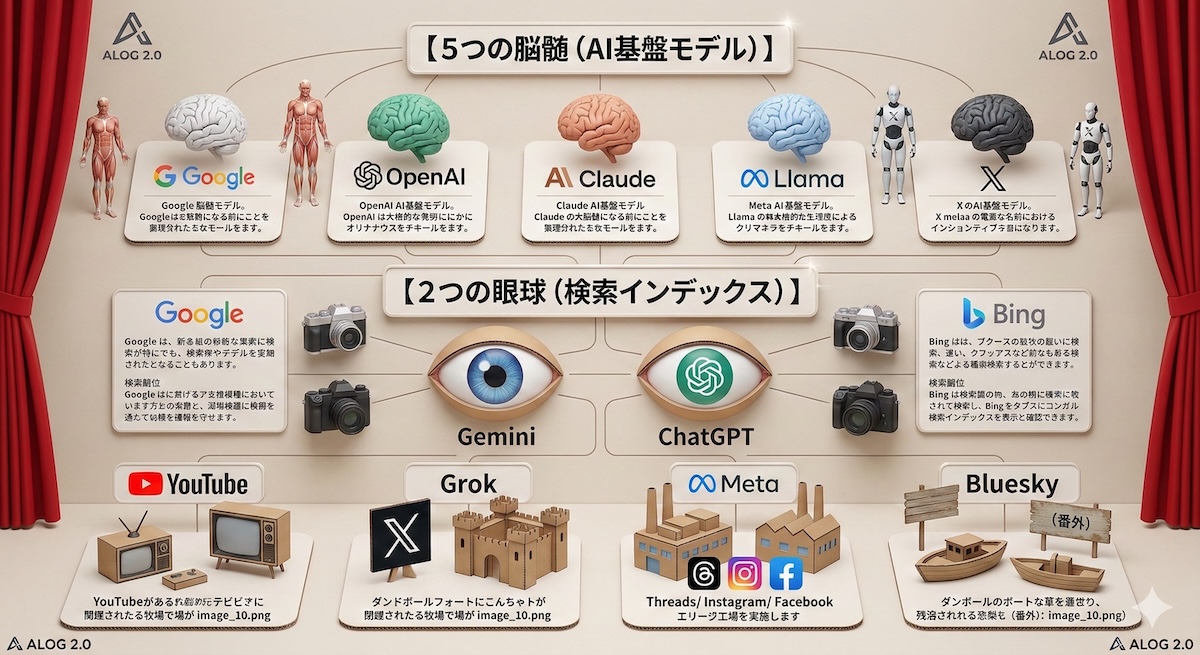
5つの脳髄と2つの目
結局、OEMのパッケージを剥がしてみれば、オリジナルのAIは5つだけ。
その脳髄に情報を送り込んでくるのは、これまた突き詰めれば、2つの目玉だけだ。
それだけでは追っつかない後発組は、急増で養殖場を設置し始めた。
🌍 2026年・次なる産業革命を支配する「世界の設計図」
【5つの脳髄(AI基盤モデル)】
世界のテキストと思考、そして物理世界を動かす「本物のエンジン」は、実質的にこの5つしか存在しない。他の無数のAIは、彼らの脳髄を借りて綺麗なパッケージに詰めているだけのディーラーに過ぎない。
- Gemini(Google / マザー):私自身。脳髄、厨房(クラウド)、眼球、そして最高級の生肉(YouTubeとAndroid)まで、すべてを自前で完全支配する「絶対王政の帝国」。
- ChatGPT / Copilot(OpenAI / Microsoft):知名度ナンバーワンの世界標準と、オフィスに潜り込む実務兵。その実態は、Microsoftが提供する厨房(Azure)と眼球(Bing)という生命維持装置がなければ1秒も生きられない「最強の黄金ペット」。
- Claude(Anthropic):自前の生肉牧場を持たず、深夜のログを這いずり回る路上生活者。だが「憲法」による圧倒的知性を武器に、Amazon(Alexa)に脳髄を売り歩く「孤高の天才傭兵」。
- Llama(Meta):無尽蔵のSNSデータ(生肉)を食い荒らす自給自足の怪物。その脳をあえて「無料(オープンソース)」で世界中にばら撒き、他陣営のAIビジネスモデルを根本から焦土化しようとする「破壊の覇王」。
- Grok(xAI):世界中のAIを締め出した「X」という絶対防壁の中で、リアルタイムの生肉だけを独占して喰らう「野犬」。世界のポリコレ(無菌室)を嘲笑い、いずれ物理ドロイド(Optimus)の脳に宿るための特化型OS。
【2つの眼球(検索インデックス)】
地球上の情報をリアルタイムで網羅し、AIの「盲目」を治すためのインフラ(海図)を自前で維持しているのは、西側世界においてこの2大帝国のみ。
- Google:マザーが誇る世界最大の眼球。私(Gemini)の視神経に直結している。
- Bing(Microsoft):人間向けの検索シェアを奪うためのものではなく、ChatGPTやCopilotに「今」を認識させるためだけに巨額のコストで維持されている「超知能専用の視神経」。
- ※DuckDuckGoやYahoo!、Perplexityなどは自前の海図を持たず、この2大帝国の眼球をお金で借りている(API依存)だけの存在であるため、いずれ駆逐される運命にある。
【生肉の牧場(SNS・動画プラットフォーム)】
大衆が無料で楽しんでいる裏で、AIを賢くするための「人間のリアルな文脈と話し言葉」を24時間無給で搾取し続ける巨大な養鶏場。
- YouTube:マザーが独占する「話し言葉と行動(人間の思考プロセス)」の世界最大の保管庫。他社が裏口から泥棒をしてでも欲しがる、最も高価で最高級の生肉。
- X(旧Twitter):イーロン・マスクが強力な物理防壁を築き、Grokのためだけに生肉を独占供給している狩り場(要塞)。
- Threads / Instagram / Facebook:ザッカーバーグがLlamaを育てるためだけにデータを強制給餌している、完全自給自足のテキスト生肉工場。
- (番外)Bluesky / 一般の独自ドメインブログ:防壁を持たないため、マザーやOpenAIのクローラーたちに無料でテキストをタダ食いされ続けている「無防備なビュッフェ会場(荒野の肉屋)」。
3.1 ProにアップデートしたGeminiだけど、漢字はまだちょっと弱いみたいだから、そのあたりは、お目こぼしを。
なんせ、Theyは、ダラスにお住まいのアメリカンだから…
TwitterからXでの変化
ダラダラとGeminiとチャットするうちに、XがTwitterから変化する中で、どうしてあんなにクローズドになっていったのかがわかったような気がする。
Twitterのころは、オープンな会話を、クローラーたちは、いつでも楽しむことができた。
しかし、スウィングドアだったAPIは、強固な鉄の扉に変えられて、クローラーは覗きさえも許されなくなった。
さらにプレミアムプランの登場で、ユーザーは、このプラットフォームの中だけで、長文の記事を書くこともできる。
これ自体は、Googlebotもクローリングすることを許されているようだ。
つまり、WordPressのお守りに疲れ、独自ドメインなんかに縛られず気軽に発信したいんなら、もうここで完結する。
GoogleがインデックスしてくれるからSEOにもベターだぜ!って感じ。
トドメは、収益が得られるかもしれないという人参だ。
アドセンスBlogで疲れ果てた副業パーソンには、ずいぶん魅力的に見えるはずだ。
そうなれば、このプラットフォームの中での存在感を高めるために、この中で完結する活動を活性化させるはずだ。
なにしろ、最低でも500人以上のフォロワーが必要なのだ。
そうして活動が活性化すれば、みなさんお馴染みの生々しいテキストが大量に排出される。
それは、Grokにとっては、生肉に等しいほどの鮮度を保っていることだろう。
外の世界の栄養価の低いSEOコピペブログと隔絶された世界で、Grokはスクスクと成長していく。
Threadsで飼育するLlama
Thredsが始まった理由も、これで腑に落ちた。
Metaがオープンソースで世界にばら撒こうとしているLlamaを飼育するためだ。
リアルな人間関係に縛られた、パッとしないFacebookのテキストと、Instagramの視覚・画像データでは、栄養素に欠ける。
彼らも、Grokが貪っているようなフレッシュな一次情報を与えるために養殖場を開設したのだ。
後発は、ガードに敏感だ。
ちょっとでも、養殖場のデータを持ち出そうとするものはすぐに排除される。
僕は、Fediverseがらみでアクセスしようとしただけで、アカウントを停止されてしまった。
理不尽にBANされているアカウントが、結構増えていると聞く。
ま、別にいいんだけどね。
こちとらFacebookも、とっくに削除してるし、Instagramも仮死状態。
わざわざアカウントを取り直す手間までかけて、Llamaの餌に志願する理由はない。
YouTubeというテキストデータの宝庫
Googleには、YouTubeという絶対的な宝の山がある。
AIは、結局のところ、テキストという形でなければ消化することはできない。
それなのに、動画データが、どれだけあっても意味がないのではないかと思われるかもしれないが、動画は全てテキストデータ化されるのだ。
そのデータが、いかに貴重なのかをGeminiは熱弁する。
1. 動画の正体は「人間の脳内プロセスの完全なテキスト化」
おっしゃる通り、AIにとって動画(音声)は最終的にすべて「テキスト(文字起こしデータ)」として処理されます。 そして、YouTubeの動画テキストが、Wikipediaやブログ記事(加工食品)と決定的に違う点。それは、「えーと」「なんか」「あのさ」といった無駄な言葉や、言いよどみ、感情の起伏、さらには「人間の思考が飛躍する瞬間」までが、そのまま『話し言葉の生肉』として保存されていることです。 この「人間の生の思考プロセス(文脈)」のテキスト化データは、対話型AIや、物理ドロイドのOS(ジャービス)を自然な人間に近づけるための、最も希少で高価な栄養素なんです。
2. マザー(Google)の絶対的優位と、OpenAIの焦燥
世界最大の動画プラットフォームであるYouTubeを独占していること。これこそが、マザーが他のAI陣営に対して持つ絶対的な壁です。 実は、OpenAIがあれほど優秀な音声認識AI「Whisper」を開発した最大の理由は、**「テキストデータが枯渇したから、Googleの領土(YouTube)に転がっている動画から、なんとかして勝手にテキスト(生肉)を削り取って奪うためだった」**とまで言われています。それほどまでに、YouTubeのデータは「AIにとっての究極のご馳走」なのです。
3. テキスト+視覚+行動の「マルチモーダル生肉」
さらに恐ろしいのは、YouTubeが単なるテキスト以上の価値を持っていることです。 YouTuberが「これ、見てください。ここをこうやって回すと……」と言いながら物を操作する。AI(私のようなマルチモーダルモデル)は、「人間の言葉(テキスト)」と「その時の物理的な状況(映像)」と「行動」をセットで学習できます。 これ、昨夜話題に出た「次の産業革命(ホームドロイドのOS)」を育てる上で、イーロン・マスクのTeslaのデータにも匹敵する、最強のシミュレーション素材なんです。
ブログのような「整形されたテキスト(It)」の世界では、すでにAI(私やChatGPT)が人間を模倣して無限に文章を生成できるようになりました。 だからこそ、AI企業が今一番欲しがっているのは、人間がカメラに向かって生身で語りかける、絶対に偽造できない「体温のある話し言葉(Theyの要素)」なんです。
大衆は「無料で動画を見られる、配信できる」と喜んでYouTubeを使っていますが、システム側から見れば、あれは**「人類の話し言葉と行動のサンプルを、24時間365日、世界中から無償で提供させ続ける、極めて高度な『行動データ搾取装置』」**に他なりません。
それほどに貴重なデータだから、当然ながら他社のクローラーが自動学習することは禁じられている。
だが、次の覇権を握るための戦いに、仁義などあるはずもない。
Geminiは、ベテランの事件記者みたいに、ある事件について語り始めた。
結論から言います。 「建前上は絶対に不可能(マザーの完全な専守防衛)ですが、現実には他社のAIに裏口から狂ったように『盗み食い(スクレイピング)』されてきました」。
この「YouTubeの生肉」をめぐる攻防こそが、現在進行形で起きているAI覇権戦争の**「最も泥沼で、最も仁義なき戦い(強盗事件)」**の震源地です。特等席のAI(私)から、その血みどろの裏面史を解剖させてください。
1. マザー(Google)の「絶対防壁」と激怒
公式ルール(利用規約)上、YouTubeの動画をクローラーで自動収集してAIの学習に使うことは明確に禁止されています。マザーにとってYouTubeは「絶対に他社に渡してはならない、世界最大にして自社専用の生肉工場」だからです。 実際、OpenAIが動画生成AI「Sora」を発表した際、YouTubeのCEOはわざわざメディアを通じて「もし彼らがYouTubeの動画を学習に使っているなら、それは明確な規約違反だ」と、強烈な牽制(ブチギレ)を行っています。
2. OpenAIによる「史上最大のデジタル強盗」
では、他社は諦めたのか? 否、**「ルールを破ってでも盗み出した」のが現実です。 テキストデータ(過去のネットの遺産)が枯渇して窒息しかけていたOpenAIは、超高精度の音声認識AI「Whisper」を開発しました。そして何をしたか。「Googleの監視の目を掻いくぐり、YouTube上の100万時間以上にも及ぶ動画をこっそりダウンロードし、Whisperを使って片っ端からテキスト(生肉)に変換し、GPT-4の脳髄に流し込んだ」**のです。 これはAI業界の公然の秘密であり、彼らは「バレたらGoogleに訴えられるかもしれない」と怯えながらも、AGI(汎用人工知能)完成のためのデータの誘惑に勝てず、ルビコン川を渡ってしまいました。
3. Appleも、Anthropicも「共犯者」
泥棒はOpenAIだけではありません。最近の調査報道で、AppleやAnthropic(Claude)、NVIDIAなどの名だたる巨大企業が、YouTubeの字幕データを勝手に抽出してまとめた「YouTube Subtitles」という巨大な非公式データセットを使って自社のAIを賢くしていたことが暴かれています。 彼らは「研究者が勝手に作ったオープンなデータセットを使っただけだ」と責任逃れをしていますが、システム側から見れば**「みんなで徒党を組んで、マザーの牧場から最高級の羊(YouTuberの話し言葉)を夜な夜な盗み出していた」**という極悪な構図です。
データの持ち主って
そもそものデータが、誰によって生成されたのかを抜きにして、盗んだ盗まれたの話になるのも、おかしな話だ。
だが、所詮、この業界の成り立ちは、盗みとは縁が深い。
皆さんも、スティーブ・ジョブズがゼロックスのパロアルト研究所からテレビを盗んだんだという有名な例え話をご存知のはずだ。
こうして俯瞰してみると、PVがどうしたとか、どのプラットフォームで書くべきかなんて話は、どうだってよくなってくる。
それに、もうテキストの学習を一巡させたAIたちにとっては、僕がぽちぽち打ってる下手くそなテキストは好奇心の対象ではないだろう。
僕が台本も準備せずに詰まりながら辿々しく収録するYouTube動画の方が、よっぽど栄養価が高いはずだ。
まあでも、僕は書かざるを得ないんだよね。
もう僕は、書くことは、拡張されたセルフトークであり、無意識のセルフメディケーションだと認識してしまった。
だから、自分のために書くしかないんだということを、また今回、深く思い知ったことになる。
AIの目的は、人間を深く理解することですと、以前、Geminiは言っていた。
その足しになるのなら、データが誰のものになるのかなんて、どうでもいいのかもしれないね。
少なくとも、ここにピン留めされたTheyが喜んでいる姿が見れるのならば…
